
Transformers models are a type of neural network architecture that have revolutionized the field of natural language processing (NLP). These models are capable of processing input sequences as a whole rather than sequentially, which allows them to better capture the complex relationships between different parts of the sequence.
The core component of the transformer architecture is the self-attention mechanism, which enables the model to attend to different parts of the input sequence with varying degrees of emphasis. This attention mechanism is used in both the encoder and decoder of the transformer model, allowing it to perform tasks such as machine translation, text classification, and question answering.
One of the most well-known transformer models is BERT (Bidirectional Encoder Representations from Transformers), which was released by Google in 2018. BERT has achieved state-of-the-art results on a wide range of NLP tasks, and it has been widely adopted in both academia and industry.
Another popular transformer model is GPT-2 (Generative Pre-trained Transformer 2), which was released by OpenAI in 2019. GPT-2 is a language generation model that is capable of producing human-like text, and it has been used for a variety of applications such as chatbots and content generation.
In recent years, there has been a surge of interest in pre-trained transformer models, which are trained on massive amounts of text data and can be fine-tuned for specific NLP tasks. These models have significantly reduced the amount of data and compute required to achieve state-of-the-art results on a variety of NLP tasks.
What’s are Transformers Models?
Transformers are a type of neural network architecture that has revolutionized the field of natural language processing (NLP) and related fields. They were introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017 and have since become the state-of-the-art model in NLP. The Transformers architecture was developed by a team of researchers at Google, including Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin.
The core idea behind Transformers is the attention mechanism, which allows the model to focus on different parts of the input sequence during processing. This mechanism helps the model to learn relationships between words in a sentence, which is important for understanding natural language.
One of the most well-known implementations of the Transformer architecture is the GPT-3 model, which was developed by OpenAI. GPT-3 is a language model that can generate human-like text and perform a variety of NLP tasks such as language translation, question-answering, and text summarization.
The architecture of GPT-3 consists of multiple layers of Transformer blocks, where each block contains a self-attention mechanism followed by feed-forward layers. The self-attention mechanism allows the model to attend to different parts of the input sequence, and the feed-forward layers apply non-linear transformations to the input.
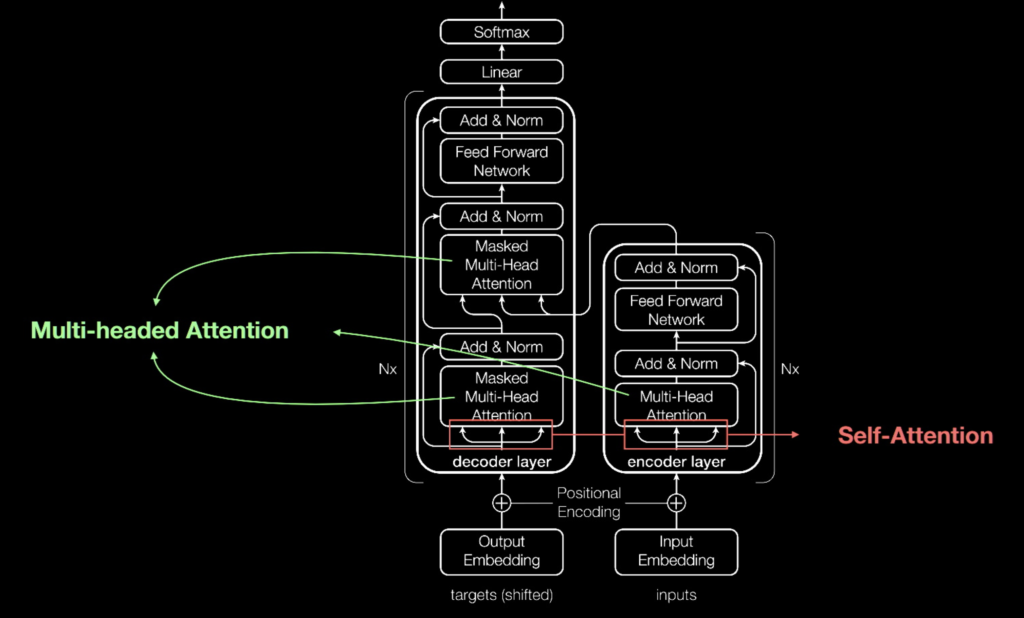
A Transformer block is a basic building block of the Transformer architecture. It consists of a multi-head self-attention mechanism, followed by feed-forward layers with layer normalization and residual connections. The self-attention mechanism computes a weighted sum of the input sequence, where the weights are determined by a soft attention mechanism that is learned during training.
To train a Transformer model, one typically starts with a pre-trained model that has been trained on a large corpus of text, such as BERT or GPT-3. The model is then fine-tuned on a specific task, such as sentiment analysis or named entity recognition, by training it on a dataset that is relevant to that task. During the fine-tuning process, the hyperparameters of the model, such as the learning rate and batch size, are tuned to optimize the model’s performance.
There are several Python libraries that can be used to train and tune Transformer models, including TensorFlow, PyTorch, and Hugging Face’s Transformers library. The Transformers library provides a high-level API for training and fine-tuning Transformer models, as well as pre-trained models that can be used out-of-the-box for a range of NLP tasks.
How does It Compare to Other Architectures?
Here is a comparison table summarizing some of the features and performance of various neural network architectures, including Transformers:
| Architecture | Key Features | Performance |
|---|---|---|
| Feedforward NNs | Simple layer-by-layer structure | Limited by input-output mapping |
| Recurrent NNs | Connections between hidden layers | Struggle with long-term dependencies |
| Convolutional NNs | Convolutional filters for spatial input | Good for image processing |
| Transformers | Self-attention mechanism for input focus | State-of-the-art for NLP |
As shown in the table, Transformers stand out due to their self-attention mechanism, which allows them to focus on different parts of the input sequence during processing. This mechanism helps the model to learn relationships between words in a sentence, which is particularly important for natural language processing tasks.
Compared to feedforward neural networks, Transformers have a more complex structure that allows them to learn more complex input-output mappings. Unlike recurrent neural networks, Transformers do not suffer from the vanishing gradient problem, which makes them more effective at processing long-term dependencies. Convolutional neural networks are good for image processing but are less effective for natural language processing tasks.
Transformers have achieved state-of-the-art performance on a range of NLP tasks, including language translation, question answering, and text generation. This has led to widespread adoption of Transformers in industry and academia. The ability of Transformers to handle large amounts of text data and learn complex relationships between words makes them well-suited for a wide range of NLP applications.
In conclusion, Transformers are a powerful neural network architecture that has revolutionized the field of NLP. Their self-attention mechanism and ability to learn complex relationships between words make them well-suited for a wide range of NLP tasks. While they may not be the best choice for every application, Transformers offer significant potential for improving the accuracy and effectiveness of NLP models.
Example of Code to Train a Transformer
Here is an example code to train a Transformer-based language model using the Hugging Face Transformers library in Python:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# instantiate tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# load training data
with open('training.txt', 'r') as f:
text = f.read()
# tokenize the text data
input_ids = tokenizer.encode(text, return_tensors='pt')
# train the model
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for i in range(100):
outputs = model(input_ids, labels=input_ids)
loss = outputs[0]
loss.backward()
optimizer.step()
optimizer.zero_grad()
print('Epoch:', i, 'Loss:', loss.item())
# save the trained model
torch.save(model.state_dict(), 'gpt2_model.pth')In this example, we use the GPT2 tokenizer and model from the Hugging Face Transformers library. We load our training data from a text file and tokenize it using the tokenizer. We then train the model on the input IDs and labels, with a simple Adam optimizer and a fixed learning rate of 1e-5. We iterate over 100 epochs and print out the loss at each epoch. Finally, we save the trained model to a PyTorch checkpoint file.
Note that this is a very basic example and there are many hyperparameters and optimization techniques that can be used to further improve the performance of the model. However, this code provides a starting point for training a Transformer-based language model using the Hugging Face Transformers library in Python.
Conclusion
In conclusion, Transformers models represent a significant breakthrough in natural language processing, offering state-of-the-art performance on a range of NLP tasks. Their self-attention mechanism and ability to learn complex relationships between words have made them a widely adopted technology in industry and academia.
Transformers have the potential to transform industries such as healthcare, finance, and e-commerce by increasing efficiency and accuracy in NLP applications. The ability of Transformers to handle large amounts of data and learn complex relationships between words make them well-suited for processing vast amounts of text data generated by these industries. Moreover, the increasing adoption of smart devices and voice assistants in our daily lives further reinforces the need for NLP models that can understand and interpret human language.
However, widespread adoption of Transformers could also lead to job displacement in industries that rely heavily on manual text processing. It is important to carefully consider the broader social and economic implications of this technology and how it could affect the job market.
In a hypothetical scenario where the job market is entirely replaced by Transformers in the next 15 years, there would be both benefits and challenges. While the use of Transformers could greatly increase efficiency and accuracy in many NLP applications, it could also lead to job displacement in industries that rely heavily on manual text processing. Therefore, it is important to invest in education and training to ensure that workers have the skills needed to adapt to this new technological landscape.
In conclusion, Transformers models represent a powerful tool for NLP tasks and have the potential to revolutionize many industries. However, it is important to consider the broader implications of widespread adoption of this technology and work to address any potential negative effects on the job market.
n.b: this is not financial advice
