
In recent years, Generative Adversarial Networks (GANs) have sparked a lot of interest in research and engineering circles. They have emerged as a new and powerful method for learning how to generate realistic data. GANs are expected to grow rapidly and play an important role in a variety of fields, including computer vision.
GANs have recently been used as a method to generate high quality images from low quality data. They are also capable of generating images from simple textual data, such as sentences describing images. You could say they are the trend these days.
In this article, we will introduce GANs, how they work, their types and their use cases.
What is a GAN?
GANs are generative models : they create new data instances that look like your training data. For example, they can create images that look like photographs of human faces, even though the faces don’t belong to any real person. These images were created by a GAN:

In 2014, when AI researchers including Ian Goodfellow introduced the use of GANs, it attracted many AI startups and companies. It is also catching up with practitioners, coders and researchers in all sectors as it matures and grows over time.
The potential of GANs for good and evil is enormous, as they can learn to mimic any data distribution. That is, they can learn to create objects extremely similar to their real-life versions in any field: images, music, speech, prose. They can also be used to generate fake media content. For example, producing false, possibly incriminating photos and videos or so-called Deepfakes.
How do GANs work?
GANs are image generation networks via an adversarial process between two distinct models, a discriminator $D$ and a generator $G$, which are trained simultaneously.
The generator model $G$ aims to capture the distribution of the input data and generate new samples belonging to the same domain, while the discriminator aims to estimate the probabilities that images come from the set of training or whether they were generated by the $G$ generator. The performance of the discrimination model is used to update the weights of the model itself and of the generator model. This means that the generator never actually sees instances of the domain and is tuned based on discrimination performance.
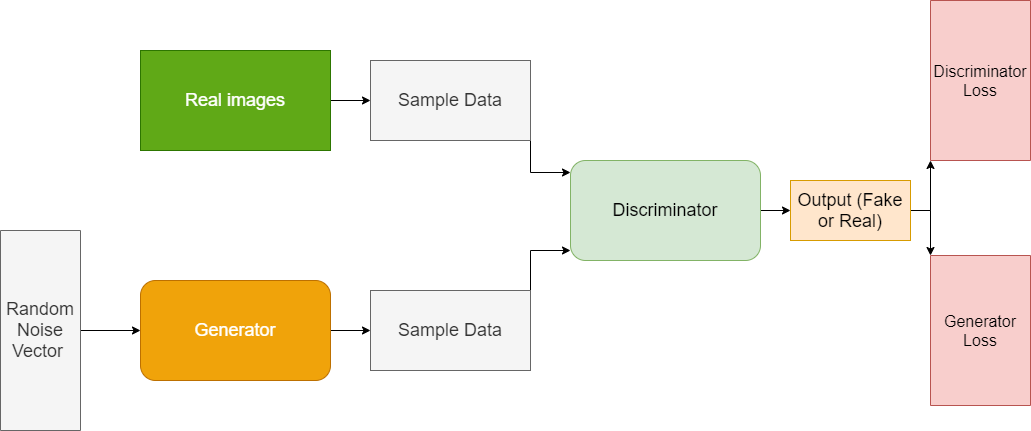
The power of adversarial networks comes from the fact that the discriminator $D$ and the generator $G$ can be nonlinear and constitute two separate neural networks that train simultaneously.
In a slightly more formal way: To learn the distribution $p_g$, the generator $G$ builds a mapping between an a priori noise distribution $p_z(z)$ and a probability distribution $p_g$= $G(z; \theta_g)$. The $D(x;\theta_d)$ discriminator returns a probability that $x$ comes from real data rather than $p_g$.
This original solution refers to the idea of the game theory problem min-max in which 2 players ($G$ and $D$) compete.
- Generator : The purpose of the generator is to learn a distribution $Y \sim p_g$ very close to the real data, so as to be able to fool the discriminator.
- Discriminator: The purpose of the discriminator is to classify the generated images $D(Y) = D(G(z))$ into two distinct classes: rehe vs fake.
The generator and the discriminator confront each other by playing a zero-sum min-max game which can be modeled by the following function $V_{GAN}(D,G)$:
$$ V_{GAN}(D,G) = \begin{cases} D: & \max_D \mathbb{E} _{x \sim p_{data}(x)}(\log D(x)) + \ mathbb{E}_{z \sim p_z(z)}(\log(1 – D(G(z)))) \\ G: & \max_G \mathbb{E}_{z \sim p_z(z) }(\log(D(G(z)))) \end{cases} $$
We want to make sure we train the discriminator $D$ to correctly classify the values of the images resulting from the real images and thus from maximize
$$\mathbb{E}_{x \sim p_{data}(x)}(\log D(x))$$
and at the same time the discriminator must be able to detect false images $G(z), z \sim p_z(z)$ by returning a probability $D(G(z))$ close to 0 by maximizing $\mathbb{ E}_{z \sim p_z(z)}(\log(1- D(G(z))))$.
The generator, meanwhile, wants to trick the discriminator, so it will learn to produce images that are increasingly similar to the distribution of real images. Thus, the purpose of the generator is to minimize $\mathbb{E}_{z \sim p_z(z)}(\log(1- D(G(z))))$.
What are the use cases?
There are several use cases for GANs, we will take a few examples:
Generation of real images of all types
The main mission of GANs is to generate real images understandable by humans, today they are able to generate images of human faces, plants, animals, and any 2D and 3D objects that do not have never existed. You can also generate images from texts, SLAB.E 2 for example, can create original and realistic images and art from a text description.
Image super-resolution
This use case serves to demonstrate the use of GANs, in particular the SRGAN model, to generate output images with higher, sometimes much higher, pixel resolution. This technique can be used to enhance satellite images.

Image-to-image translation
It’s about translating photographs across realms, such as day to night, summer to winter, and more with CycleGANs.

Photo editing
GANs can also be used to reconstruct photos of faces with specific characteristics, such as changes in hair color, style, facial expression, gender, and even face rotation angle and age. .
You can also complement, color or combine images to obtain very realistic results.

Generating other data types
Today, it is increasingly possible to create music, speech, videos, text, scents and even sound visualization using only GANs.
An example of sound visualization, a project called Neural Synesthesia. It’s about creating visual experiences from sound, starting by analyzing the audio for percussion and harmonic elements, then feeding those elements into the GAN to create a unique visual experience.
Variants of a GAN
There are many applications for generating data using GANs and there are also several variants of this network, improved versions or versions well adapted to specific cases. We will take some examples:
- StyleGAN: It is a variant of GAN, capable of generating very high resolution images. The easiest way for a GAN to generate images is to memorize the images from the training dataset and while generating new images it can add random noise to an existing image. In reality, StyleGAN does not do this, but it learns features about the human face and generates a new image of the human face that does not actually exist.
- CycleGAN: This network makes it possible to translate images between two domains A and B without having to have training data in the form of pairs of images A and B.
For example, this kind of formulation can learn a mapping function between: – artistic and realistic images. – the image of a horse and a zebra. – the winter image and the summer image.
- Conditional GAN : In cGANs, a conditional parameter is applied, which means that both the generator and the discriminator are conditioned by some sort of auxiliary information (like class labels or data) from other modalities. As a result, the ideal model can learn the multimodal mapping from inputs to outputs by being fed with different contextual information. For example, a cGAN can be conditioned to only generate images of a very specific digit (for example 1) after having been trained to generate images of the MNIST dataset. Or generate only human faces from the Face dataset.
- SRGAN: is an image super-resolution algorithm, i.e. it can resolve a low resolution image to a high resolution image.
There are other variants such as the DiscoGAN and the IsGAN.
Even if the learning of image generation models is long and difficult, because this process is very demanding in computing power, several companies and individuals consider them as an alternative and a more specific approach for data augmentation. In the case of the most complex domains, in particular Deep Learning by reinforcement, where the volume of data is limited, generative models allow a better training of the models while providing more or less unlimited volumes of data and at low cost.
